Le modèle de données de TerriSTORY¶
Introduction sur le modèle de données¶
La présente page est destinée à documenter le modèle de données sur lequel il s’appuie.
Afin d’aboutir à un système d’information fonctionnel, il faut suivre une succession d’étapes appelé le cycle d’abstraction de conception des systèmes d’information suivant le schéma suivant.
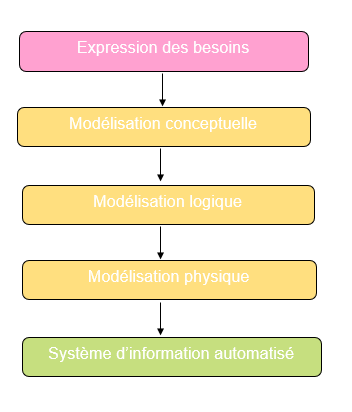
Cycle d’abstraction de conception¶
L’expression des besoins est une étape consistant à définir ce que l’on attend du système d’information automatisé, et permettant de créer un modèle conceptuel de données et de construire la structure finale de la base de données, sur laquelle l’application va s’appuyer pour tourner.
Un modèle de données est donc un modèle qui décrit la manière dont sont représentées les données et les différents liens entre les éléments qui les composent et de structurer leur stockage et leurs traitements.
Il existe plusieurs langages et méthodes de conception pour modéliser les données, nous recourons dans cette documentation à la méthode MERISE.
La modélisation Merise¶
MERISE est une méthode de conception, de développement et de réalisation de projets informatiques. Le but de cette méthode est d’arriver à concevoir un système d’information.
La méthode MERISE est basée sur la séparation des données et des traitements à effectuer en plusieurs modèles : conceptuel, logique et physique.
Nous présentons donc le modèle physique de données pour décrire le modèle de données de TerriSTORY®.
La base de données¶
Les composants d’une base de données¶
Une base de données se compose de plusieurs schémas, Un schéma représente la configuration logique de tout ou partie d’une base de données relationnelle. Chaque schéma peut comporter plusieurs tables.
La figure suivante illustre la disposition des tables et les schémas dans une base de données
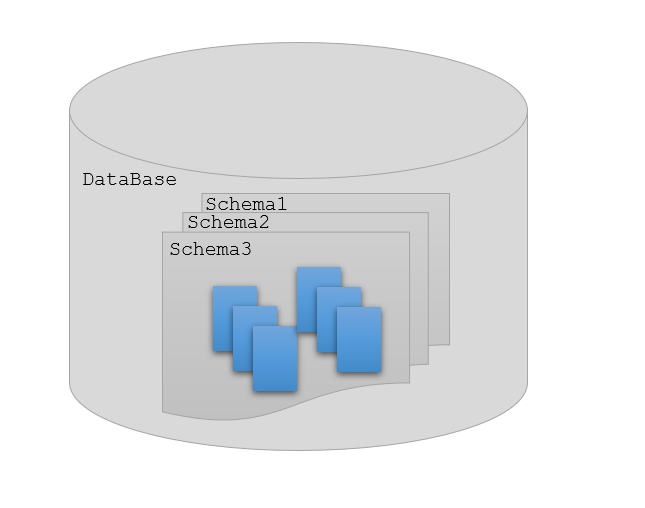
Les schémas d’une base de données¶
La base de données TerriSTORY®¶
La base de données TerriSTORY® est appelé « api », elle se compose de plusieurs schémas : des schémas communs à toutes les régions et des schémas régionaux
Les schémas régionaux comportent des tables des jeux de données pour les indicateurs, les installations, les zones territoriales disponibles, etc.
Les schémas communs comportent des données communes à toutes les régions comme les métadonnées des indicateurs, les éventuels graphiques par lesquels ils sont représentés, les tableaux de bord, les données des stratégies territoriales, les données des utilisateurs, etc.
La figure suivante illustre la disposition des tables et les schémas dans la base de données « api »

La base de données TerriSTORY®¶
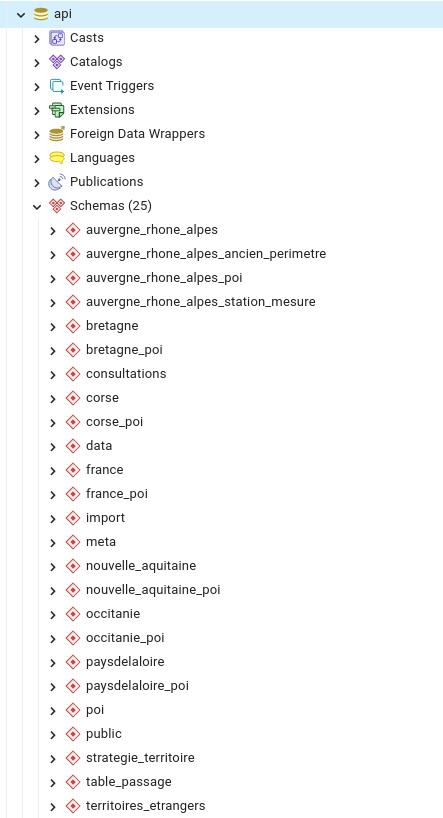
Le modèle de données TerriSTORY®¶
Le modèle de données des territoires¶
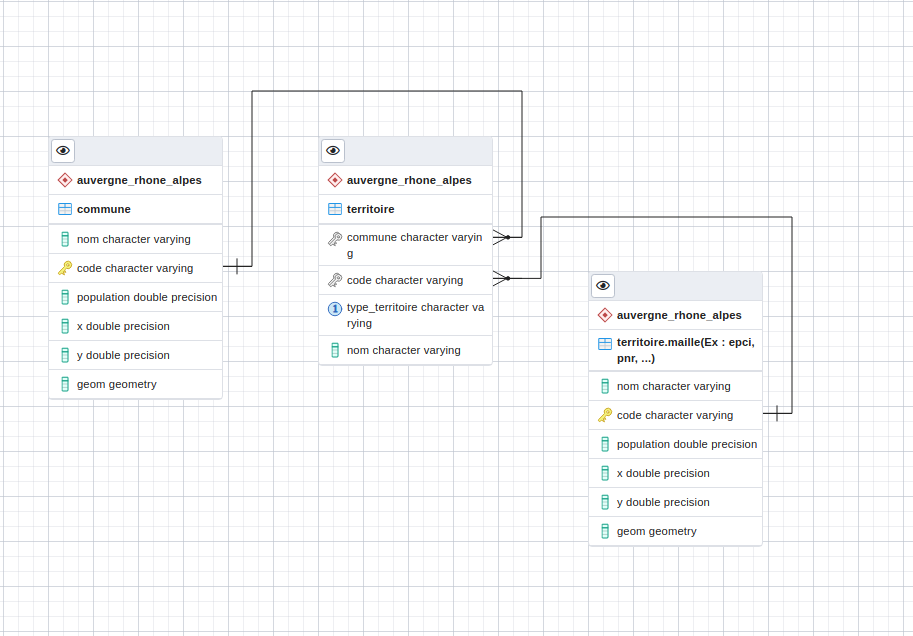
La table region.territoire contient le code INSEE des communes qui appartiennent aux différents territoires, le code du territoire qui permet de les distinguer les uns par rapport aux autres, le nom du territoire et le type de territoire dont il s’agit ( EPCI, PNR,PETR,SCOT,PPA, …)
Chaque région est découpée en communes, EPCI, PNR, etc.
Nous disposons en outre d’une table par type de territoire territoie.maille. Ces tables contiennent notamment la géométrie des frontières administratives de tous ces territoires ainsi que leur centroïde.
Le modèle de données des indicateurs¶
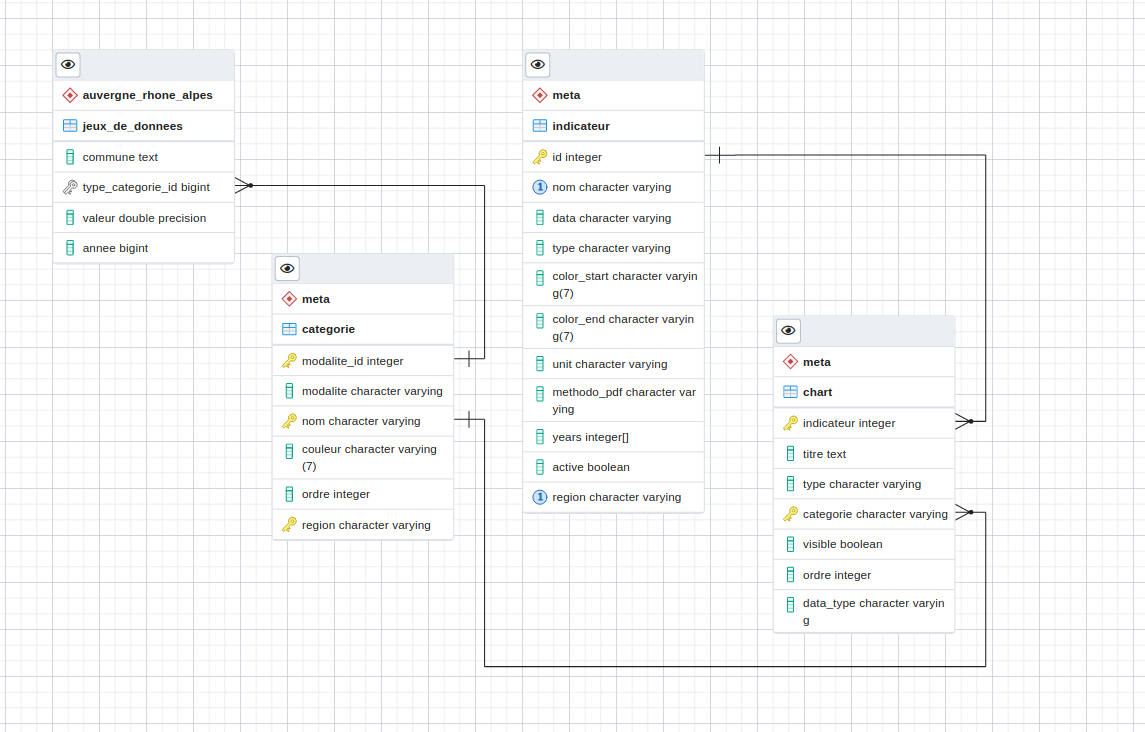
Les différents types d’indicateurs et leur mode de représentation sont décrits dans une table dédiée meta.indicateur. Cette table permet de définir chacun des indicateurs et notamment de délivrer à l’application les informations sur leur nature, leur type de représentation cartographique, les tables de données à partir desquelles ils sont construits, etc.
La table meta.categorie permet de définir les catégories des indicateurs, ces catégories sont liées aux tables des jeux de données.
La table meta.chart permet de définir les informations qui permettent d’afficher des charts graphiques dans le bandeau de bas de l’interface cartographique.
Le lien entre les territoires et les indicateurs¶
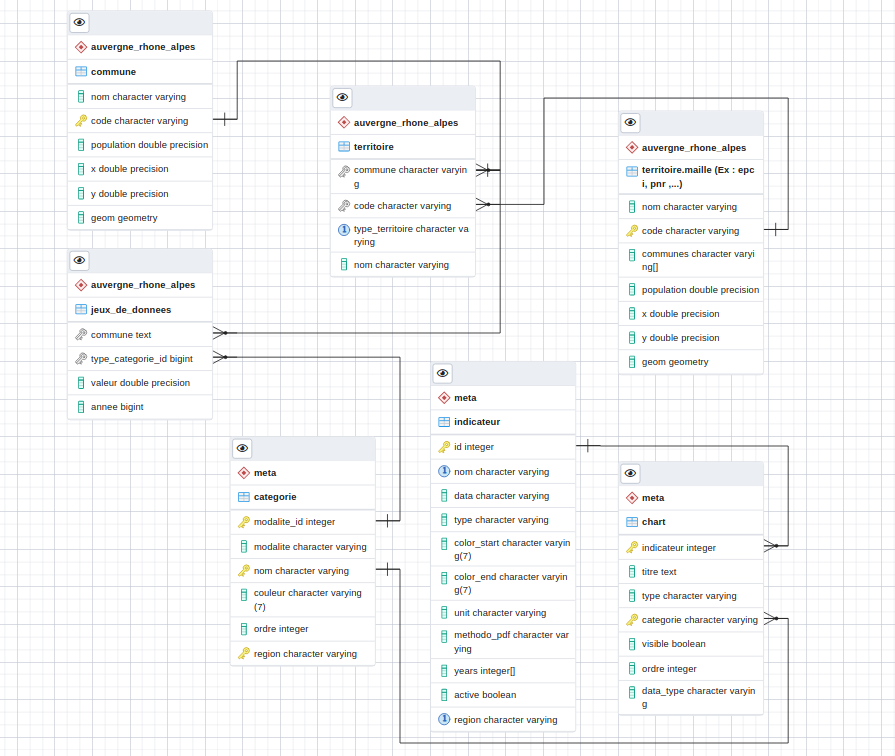
Les données à partir desquelles on calcule les indicateurs sont presque toujours déclinées à la maille communale.
Pour obtenir les données par territoire, on réalise une jointure sur la table où sont contenues les données associées à l’indicateur avec la table des territoires, et avec la table associée à la maille sélectionnée par l’utilisateur.
Le modèle de données des tables de la confidentialité¶
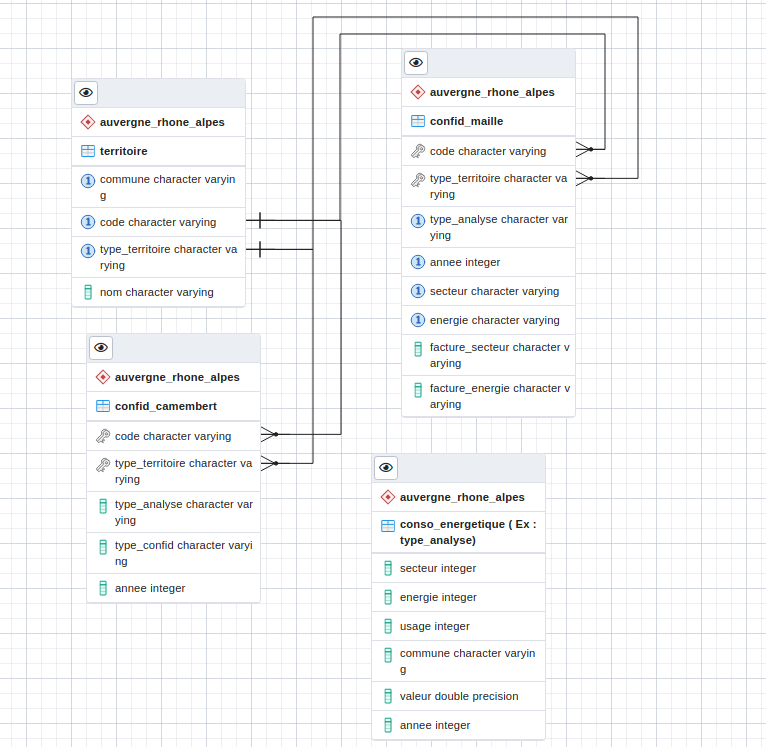
Il existe deux tables destinées à délivrer les informations relatives à la confidentialité et qui permettent ainsi de ne pas diffuser les données concernées par le secret statistique.
La table « confid_maille » destinée à masquer l’affichage cartographique des données confidentielles.
La table « confid_camembert » destinée à masquer les graphiques dans lesquels on peut lire des données confidentielles.
Le modèle de données des installations¶
Les différents types d’équipements et leur mode de représentation sont décrits dans une table dédiée « region.layer ». Cette table permet de définir chacun des équipements et notamment de délivrer à l’application les informations sur leur nature, leur type de représentation cartographique, les tables de données à partir desquelles ils sont construits (la colonne nom) etc.
Nous disposons en outre d’une table par nom de couche (region.geothermie, region.borne_irve). Ces tables contiennent notamment la géométrie des équipements ainsi que les données à afficher dans les pop-ups des équipements.
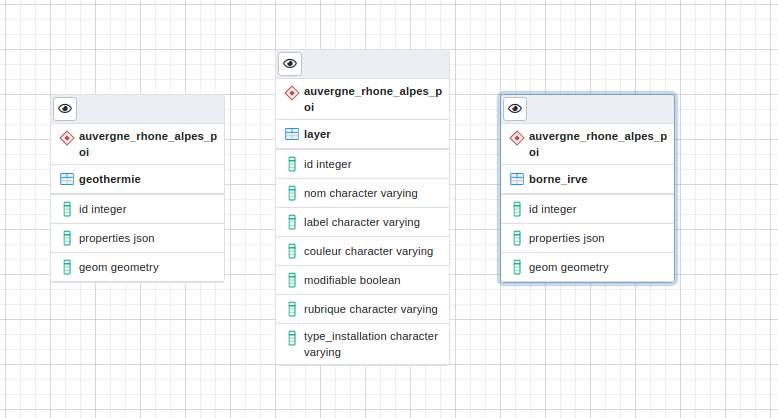
Le modèle de données de l’historique des équipements¶
TerriSTORY® offre la possibilité aux utilisateurs de modifier les données liées aux équipements, l’historique de ces modifications sont enregistrées dans la table « region.historique»
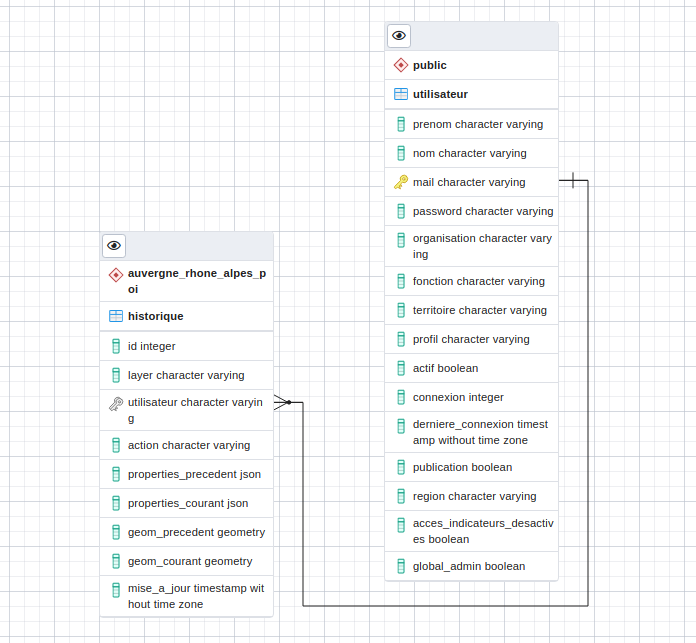
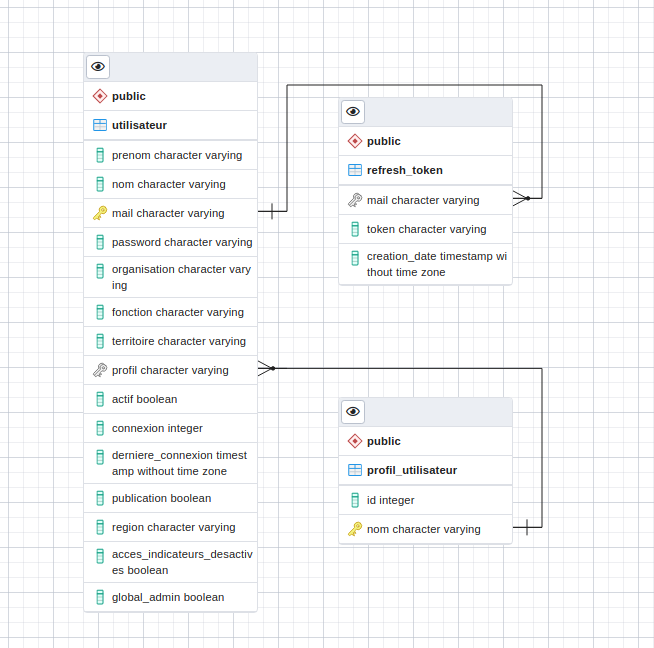
Le modèle de données utilisateurs¶
Il existe 2 types de profils dans TerriSTORY® : un profil utilisateur et un profil administrateur.
Le profil utilisateur permet de :
Créer des tableaux de bord.
Créer une stratégie territoriale.
Etc.
Le profil administrateur permet de gérer l’application :
Afficher/désactiver un indicateur
Partager un tableau de bord
Publier une stratégie territoriale
Modifier les données des équipements
Etc.
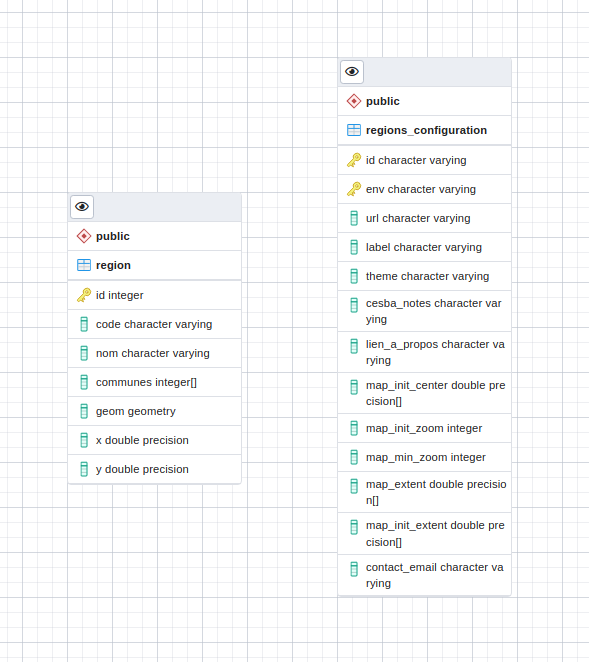
Le modèle de données des régions et leurs configurations¶
La table « public.regions_configuration » permet de stocker les différentes configuration des régions.
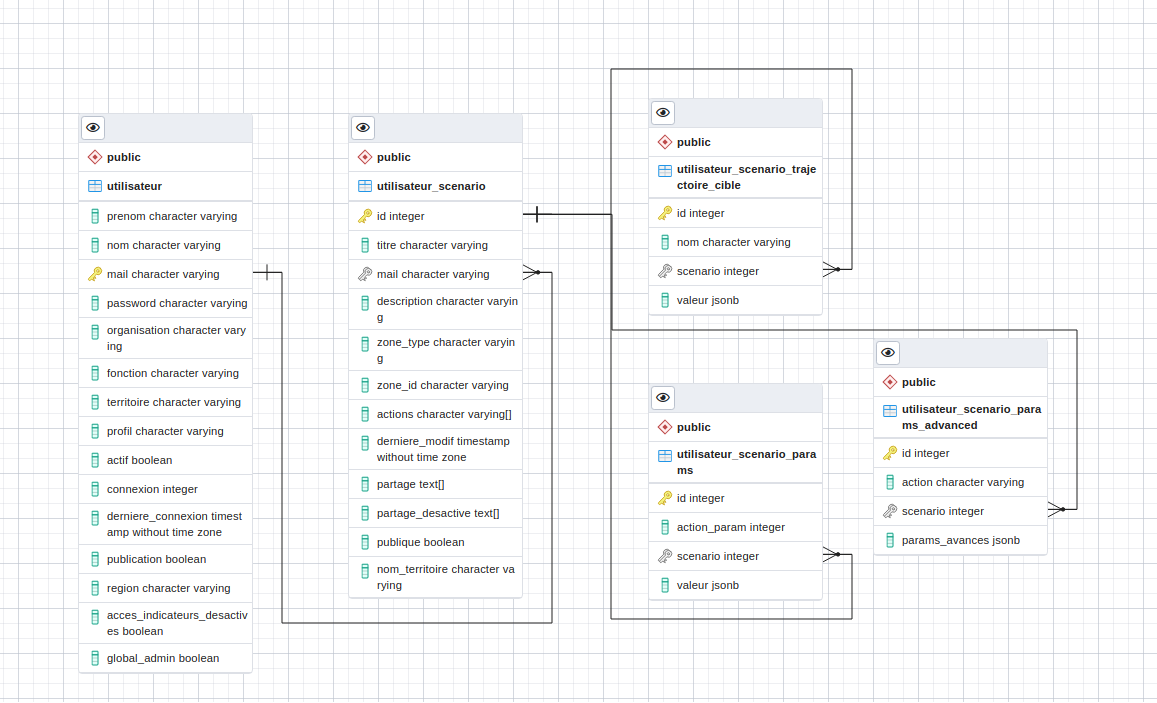
Le modèle de données des scénarios¶
Le modèle de données illustré par le diagramme ci-dessous permet d’organiser les données des utilisateurs et des stratégies territoriales qu’ils sont créées et enregistrées. La table « utilisateur_scenario » fait le lien entre les noms d’utilsateur et les identifiants des stratégies créées. Enfin, la table « utilisateur_scenario_params » contient les paramètres de chacune de ces stratégies.
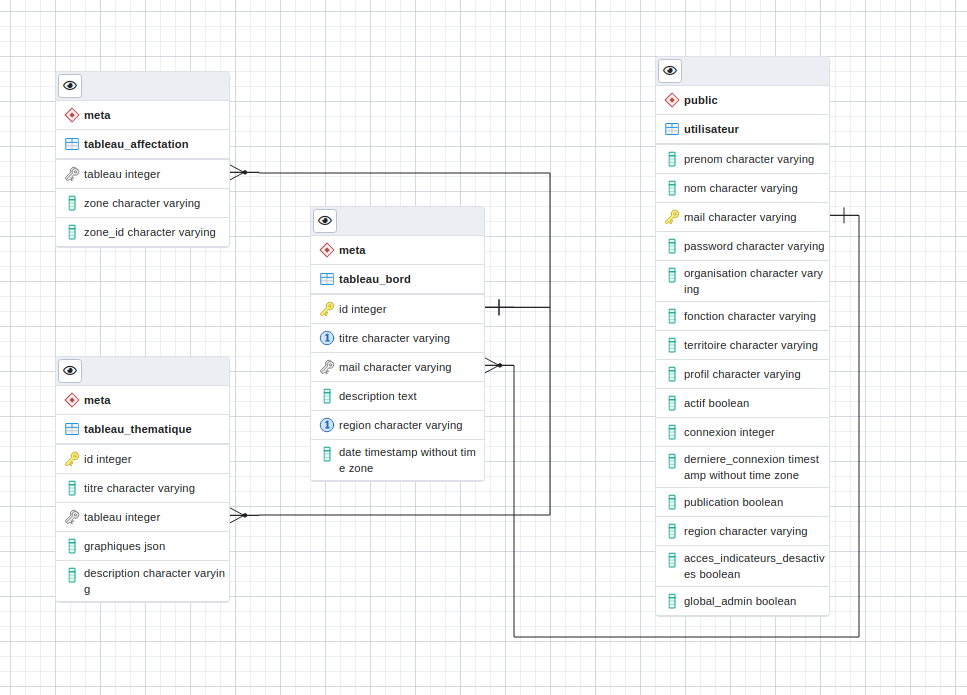
Le modèle de données des tableaux de bord¶
Les tableaux de bord créés par les utilisateurs sont enregistrés dans différentes tables sont la structure est décrite par le modèle de données ci-dessous.
La table « tableau_bord » permet d’associer un compte utilisateur grâce à son adresse mail avec un tableau de bord désigné par un identifiant unique.
On la lie avec la table « tableau_thematique » qui décrit l’organisation des thématiques et des indicateurs et leur représentation qu’elle contient.
Enfin, la table « tableau_affectation » associe les tableaux de bord à un ou plusieurs territoires / type territoires sur lesquels ils sont rendus publics (opération à laquelle seul l’administrateur en région à accès).
Le modèle de données des stratégies territoriales¶
Le module stratégie territoriale comprend plusieurs actions dont il est possible de stimuler les impacts. On peut distinguer deux types d’impacts : le impacts énergétiques, carbone et fiscaux, et les impacts économiques (investissement, valeur ajoutée et création des emplois).
On peut également distinguer deux types d’actions
Les actions de maîtrise de la consommation d’énergie
Les actions de production d’énergie
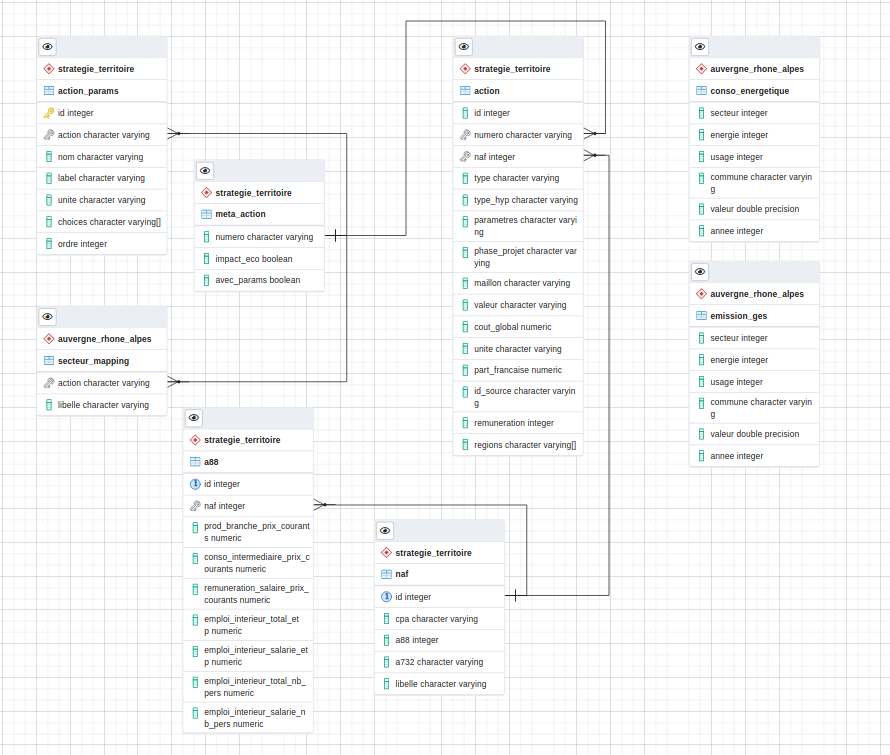
Le modèle de données des actions de maîtrise d’énergie¶
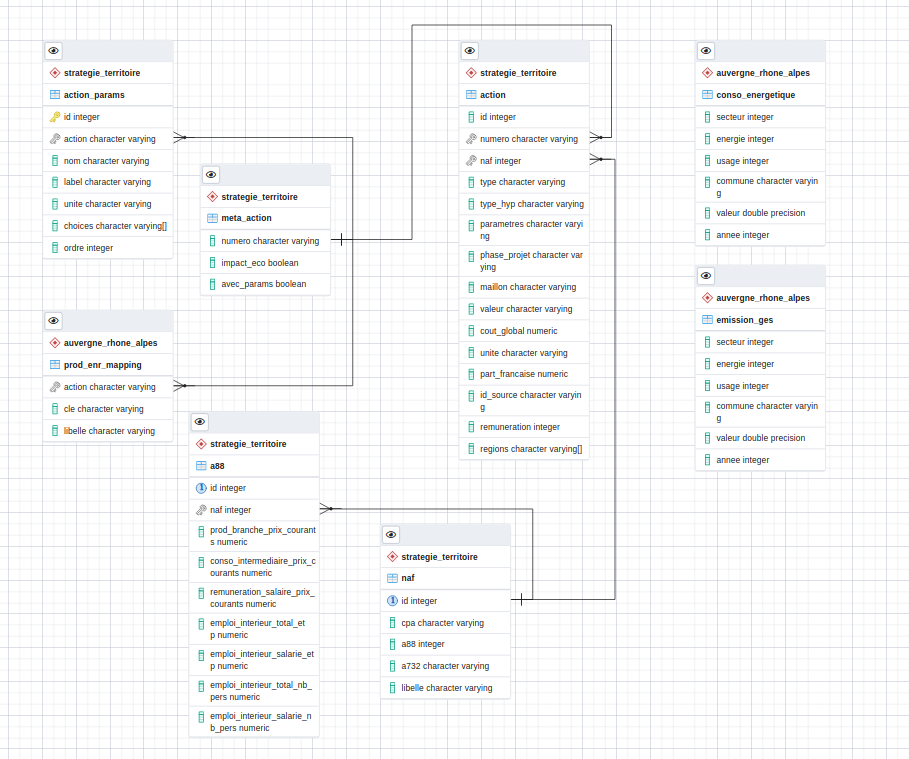
Le modèle de données des actions de production d’énergie¶
Le modèle de données des zones¶
La table « zone » permet de stocker les différentes zones à afficher dans la liste déroulante de l’interface cartographique.
Le modèle de données des objectifs supra-territoriaux¶
La module des objectifs supra-territoriaux permet aux administrateurs d’ajouter des objectifs qu’on peut faire apparaître dans les trajectoires cible et résultats d’impacts du module « stratégies territoriales ».
Le modèle de données des périmètres géographiques¶
La table « meta.perimetre_geographique » permet de stocker et délivrer à l’application les informations sur les modifications de périmètre communal entre les années successives (fusions de communes). Ces tables sont nécessaires pour la conversion des données d’un périmètre géographique à un autre.
Le modèle de données des notes synthèse territoriale¶
Le module synthèse territoriale permet de calculer des indicateurs pour les territoires d’Auvergne-Rhône-Alpes. Ces indicateurs donnent une vue d’ensemble des atouts et des faiblesses du territoire dans le domaine de l’énergie et de l’environnement.
Le modèle de données d’OpenSankey¶
Le module OpenSankey permet de visualiser un diagramme de flux énergétiques dans lequel la largeur des flèches est proportionnelle au flux représenté.
Les données utilisées pour générer ce diagramme de flux sont stockées dans la table « region.conso_energetique_sankey »
La table « meta.donnees_sankey » permet de stocker les informations sur la région, la date des données et la table qui contient les données utilisées.
Le modèle de données PCAET ADEME¶
Le modèle de données des versions d’Alembic¶
Alembic est un outil de migration de bases de données écrit par l’auteur de SQLAlchemy. Il permet de fournir un système par lequel des scripts de migration peuvent être construits ; chaque script indique une série particulière d’étapes qui peuvent « mettre à niveau » une base de données cible vers une nouvelle version, et éventuellement une série d’étapes qui peuvent « rétrograder » de la même manière, en effectuant les mêmes étapes en sens inverse.